GaussDB的架构设计解读
首页 >> GaussDB的架构设计解读1.数据库系统简介
数据库技术是对数据进行管理的数据,可以分为四部分:数据、数据库、数据库管理系统、数据库系统。
数据:可以理解成为各种描述事务的符号,比如:图片、文字、音频。
数据库:存放数据的仓库,可以对数据进行增删改查操作
数据库管理系统(DBMS):数据库与用户之间的一个接口,用于操作、管理、监控数据库,比如Mysql,Oracle,SQL Server。
数据库系统:由数据库和数据管理系统以及应用程序还有数据库管理员组成。用于存储、管理、处理和维护数据的系统。
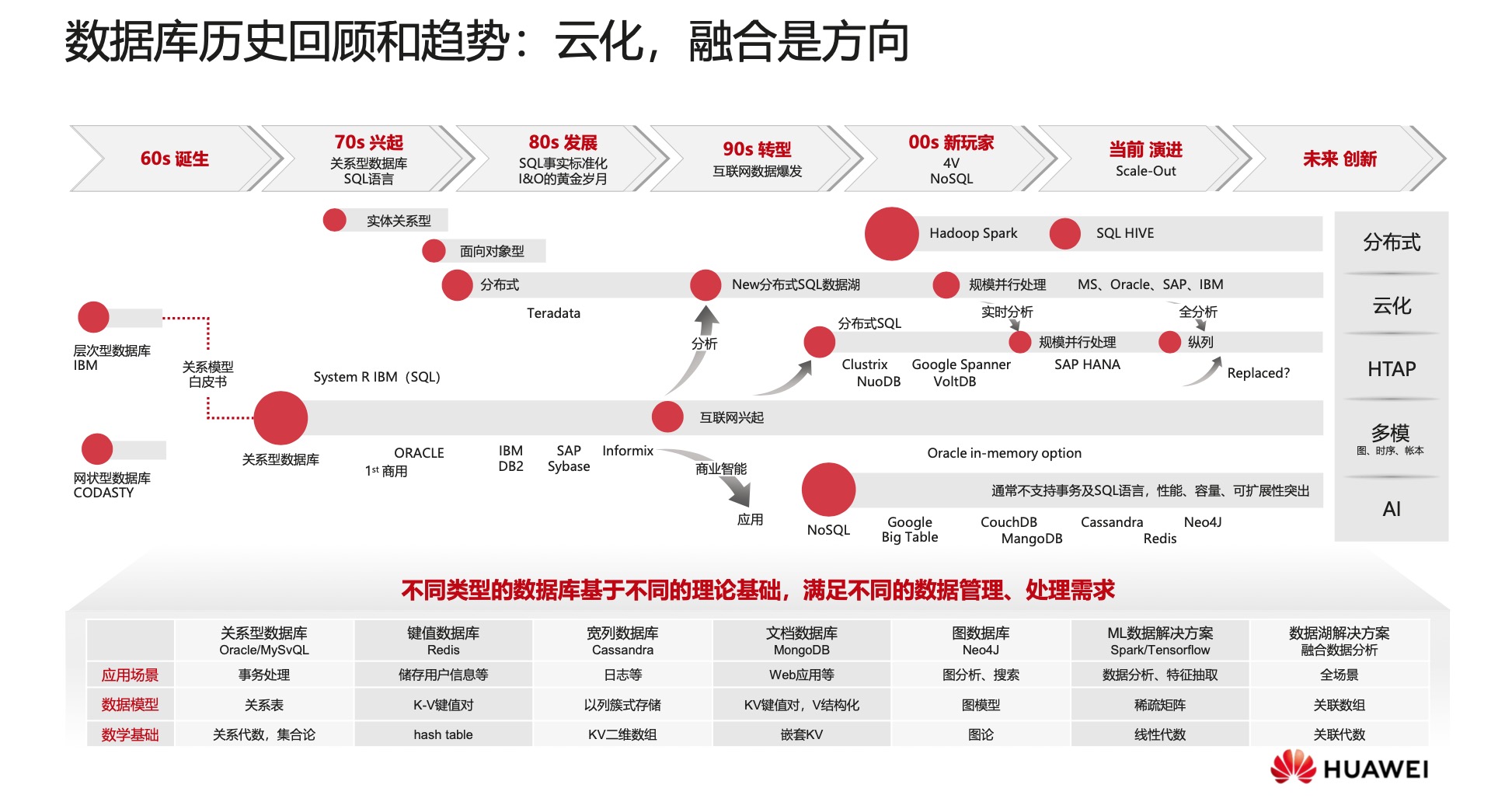
2.数据库发展的趋势
下图展示了数据库的发展历史与趋势。现在数据库的主要发展趋势是:云化、分布式、多模处理。
3.云数据库
对很多企业来说,自己管理服务器价格贵、弹性差、不易于维护,因此近几年云计算变得很流行了,直接从云服务上购买云服务,包括硬件,甚至包括诸如数据库等软件。云数据库是通过云平台构件和访问数据的数据库服务,具有传统数据库的功能,兼具云计算的灵活性。
云数据库具有以下优点:
- 低成本:企业按需付费、节约成本
- 高可用:高容错,一个节点奔溃,其它节点可以继续工作
- 易用性:开箱即用,不用关注数据库细节。
- 动态可扩展:无限可扩展性、可以满足不断的数据存储需求
- 大规模并行:并行处理能力强,面对海量数据,几乎做到实时的响应。
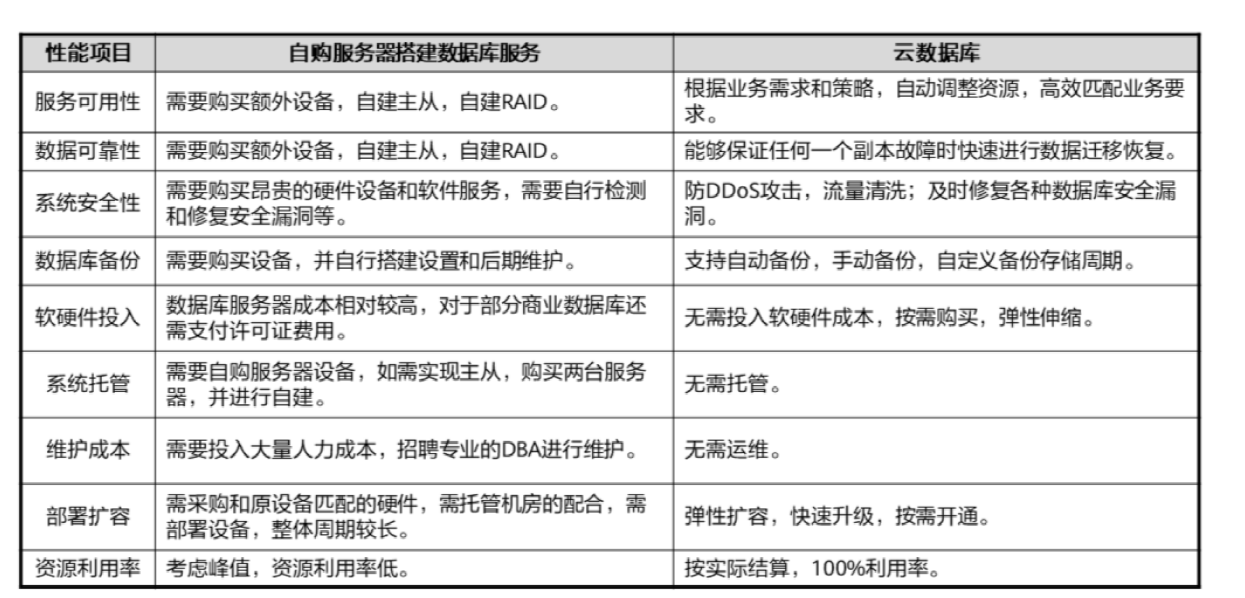
下表详细的对云数据(RDS)与传统数据库进行了对比,可以看到云数据库的优势。
4.GaussDB(for openGauss)简介
GaussDB(for openGauss)是GaussDB品牌的一款云数据库产品,深度融合华为在数据库领域多年的经验,结合企业级场景需求,推出的新一代企业级分布式数据库,支持集中式和分布式两种部署形态。
GaussDB(for openGauss)具有以下优势:
- 具备企业级复杂事务混合负载能力
- 支持优异的分布式事务
- 同城跨AZ部署,数据0丢失,支持1000+扩展能力,PB级海量存储等企业级数据库特性。
- 拥有云上高可用,高可靠,高安全,弹性伸缩,一键部署,快速备份恢复, 监控告警等关键能力,能为企业提供功能全面,稳定可靠,扩展性强,性能优越的企业级数据库服务。
同时华为开源openGauss单机主备社区版本,鼓励更多伙伴、开发者共同繁荣中国数据库生态。
4.1 GaussDB(for openGauss)的应用场景
场景一:传统核心交易
针对传统的应用,可以使用单分片的模式,使用方式同传统的主备模式相同,支持大并发、大数据量、以联机事务处理为主的交易型应用,如政务、金融、电商、O2O、电信CRM/计费等,服务能力支持高扩展、弹性扩缩,应用可按
按需选择不同的部署规模。
场景二:未来海量事务型
随着5G时代的到来,单一节点是难以应对数据规模的不断增长并确保性能的需要,而跨节点、可横向扩展的数据库可以很好解决大规模海量数据的计算存储需要。GaussDB(for openGauss)具备PB级数据负载能力,通过内存分析技术满足海量数据边入库边查询要求,适用于安全、电信、金融、物联网等行业的详单查询业务。
4.2 openGauss/GaussDB(for openGauss)/GaussDB 的关系
GaussDB是华为数据库产品品牌名,意在致敬数学家高斯(Gauss)。GaussDB系列数据库产品包括GaussDB OLTP数据库和GaussDB OLAP数据库,广泛应用于金融、政府、电信等行业。
openGauss是一款全面友好开放,携手伙伴共同打造的企业级开源关系型数据库。其下载地址是: 一款高性能、高安全、高可靠的企业级开源关系型数据库。
GaussDB(for openGauss) 是华为基于openGauss自研生态推出的企业级分布式关系型云数据库。
不久前,GaussDB(for openGauss)已经发布公共,正式更名为GaussDB。

5.GaussDB(for openGauss)软件架构
5.1 常见数据库架构设计
数据库有若干种架构设计模型,其中下图是最重要的几种。
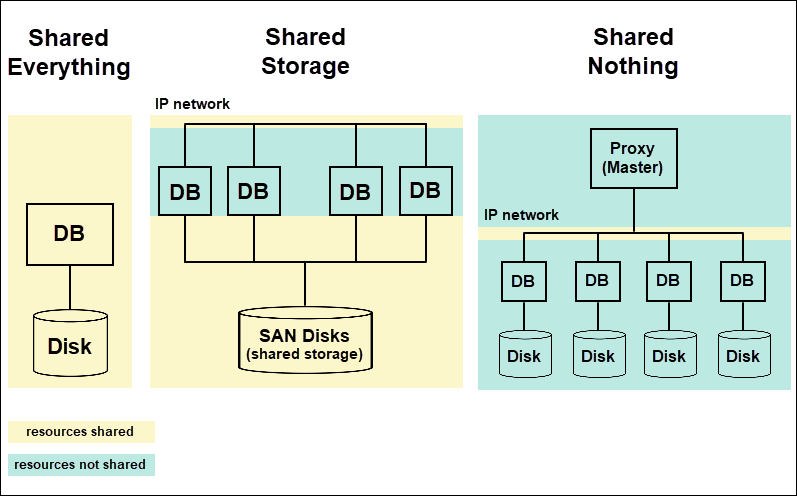
Shared Everthing
一般是针对单个主机,完全透明共享 CPU/MEMORY/IO,这种架构的并行处理能力是最差的,一般小微型,不需要考虑大并发业务的系统采用这种架构的居多。典型的代表是SQLServer。
Shared Disk
各个处理单元使用自己的私有 CPU 和 Memory,共享磁盘系统。这种体系结构有两个优点。共享磁盘系统可以扩展比共享内存系统更多的处理器。其次,它提供了一种经济的容错(fault ):如果一个节点发生故障,其他节点可以接管这个节点的任务,因为数据库驻留在所有节点都可以访问的磁盘上。
缺点是当存储器性能达到饱和时, 增加节点不能获得更高的性能
Shared Nothing(Sharding)
各个处理单元都有自己私有的 CPU / 内存 / 硬盘等,系统模型中,一组节点共享一组公共的磁盘,每个节点都有单独的处理器和内存。这种体系结构有三个优点。
- 易于扩展的架构
○ 增加节点实现性能扩展:增加节点即可增加存储、查询和加载性能。
○ 并行处理机制, 可以为BI和数据分析的高并发、大数据量计算提供高扩展能力。
- 内部处理自动化并行
○ 数据加载和访问方式与一般数据库相同。
○ 数据分布在所有的并行节点上。
○ 每个节点只处理其中一部分数据。
- 最优化的I/O处理
○ 所有的节点同时进行并行处理。
○ 节点之间完全无共享,无I/O冲突。
5.2 GaussDB(for openGauss)的架构介绍
GaussDB(for openGauss)是基于Shared-Nothing架构设计的。
它是由众多拥有独立且互不共享CPU、内存、存储等系统资源的逻辑节点组成。在这样的系统架构中,业务数据被分散存储在多个计算节点上,数据查询任务被推送到数据所在位置就近执行,通过协调节点的协调,并行地完成大规模的数据处理工作,实现对数据处理的快速响应。
5.2.1 主要模块介绍
下图是GaussDB(for openGauss)的总体架构:统一基于数据分片的分布式架构。下面介绍该架构主要的模块。
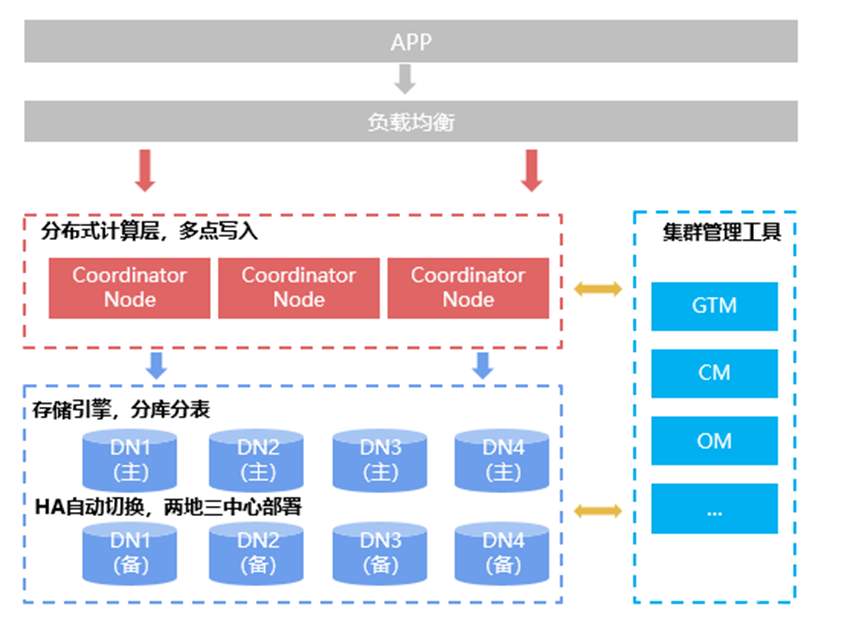
GTM(Global Transaction Manager)
全局事务管理器(Global Transaction Manager), 负责生成和维护全局事务ID、事务快照、时间戳、sequence信息等全局唯一的信息。
整个集群只有一组GTM:主GTM一个,备GTM一个或多个。
OM (Operation Manager)
运维管理模块(Operation Manager)。提供集群日常运维、配置管理的管理接口、工具。
不同于集群中的实例(GTM、CM、CN、DN)模块,OM为用户提供了相关工具对集群进行管理。
CM(Cluster Manager)
集群管理模块(Cluster Manager)。管理和监控分布式系统中各个功能单元和物理资源的运行情况,确保整个系统的稳定运行。
CN(Coordinator Node)
协调节点(Coordinator Node)。
- 负责接收来自应用的访问请求,并向客户端返回执行结果。协调分解任务,并调度任务分片在DN(Data Node)上并行执行。
- 集群中,CN可以有多个,分别部署在不同的计算节点。多个CN的角色是对等的,执行DML语句时连接到任何一个CN都可以得到一致的结果。
DN(Data Node)
数据节点(Data Node)。
负责存储业务数据(支持行存、列存、混合存储)、执行数据查询任务以及向CN返回执行结果。
- 负责存储业务数据、执行数据查询任务以及向CN返回执行结果。
- GaussDB(for openGauss)支持DN一主多备高可靠方案。在集群中,DN有多个,数量可以通过配置文件进行配置。其工作原理如下: DN主、备Quorum复制。主、备DN上均存有数据。例如,一主两备,则数据有三份。
- 任何一个DN故障,集群仍然有双份数据确保继续运行。任何一个备DN都可以升主。
- 建议将主、备DN分散部署在不同的计算节点中。
ETCD(Editable Text Configuration Daemon)
分布式键值存储系统(Editable Text Configuration Daemon)。
用于共享配置和服务发现(服务注册和查找)。
负责服务发现(Service Discovery)、消息发布与订阅、负载均衡、分布式通知与协调、分布式锁、分布式队列、集群监控与Leader竞选等功能。
5.2.2 主备版架构
GaussDB分为 分布式版 和 主备版 。
分布式形态能够支撑较大的数据量,且提供了横向扩展的能力,可以通过扩容的方式提高实例的数据容量和并发能力。
主备版适用于数据量较小,且长期来看数据不会大幅度增长,但是对数据的可靠性,以及业务的可用性有一定诉求的场景
GaussDB(for openGauss)主备版形态整体架构如下:
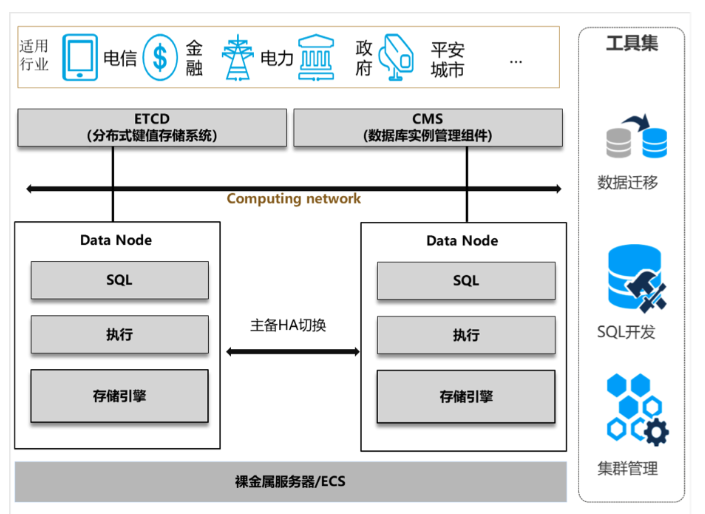
其中核心部分的细节如下图。
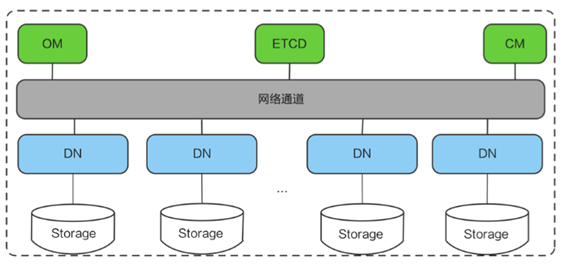
单个数据节点DN内部结构如下图。在主备模式下,所有DN存储的数据都是一致的,所有完整的数据都会存储到节点里。这与后文介绍分布式节点不同。
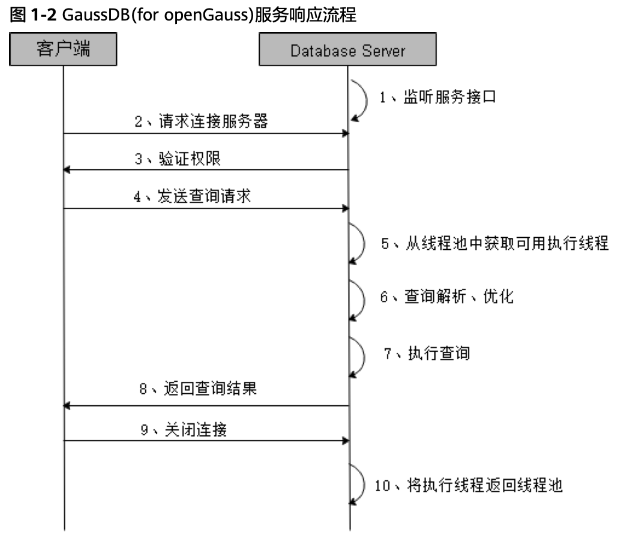
在主备模式下,一个服务响应流程可以参考下图。Database Server通过监听服务接口监听客户端,当客户端发送请求连接服务端时,服务端会进行鉴权操作。如果客户端拥有权限,则允许发送查询请求。服务端在接受到客户端的查询请求后,会从线程池中获取可用执行线程,随后进行查询解析、优化,执行查询操作。服务端获取到查询结果后,会将查询结果返回给客户端。客户端获取到结果,关闭连接,服务端会将执行线程返回线程池。
各DN中的数据信息保持一致.
一主多备(从)结构, (要求至少一主两备).
当主DN发生故障时, 任意备DN都可以升为主.
5.2.3 分布式架构
GaussDB(for openGauss)分布式形态整体架构如下:
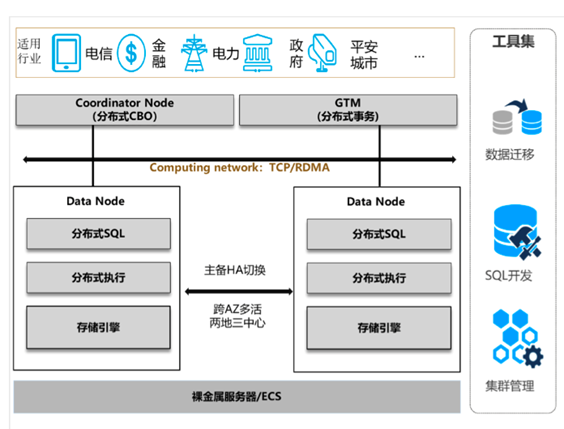
其中核心部分的细节如下图。
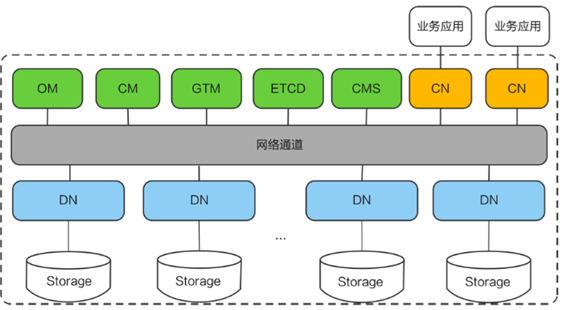
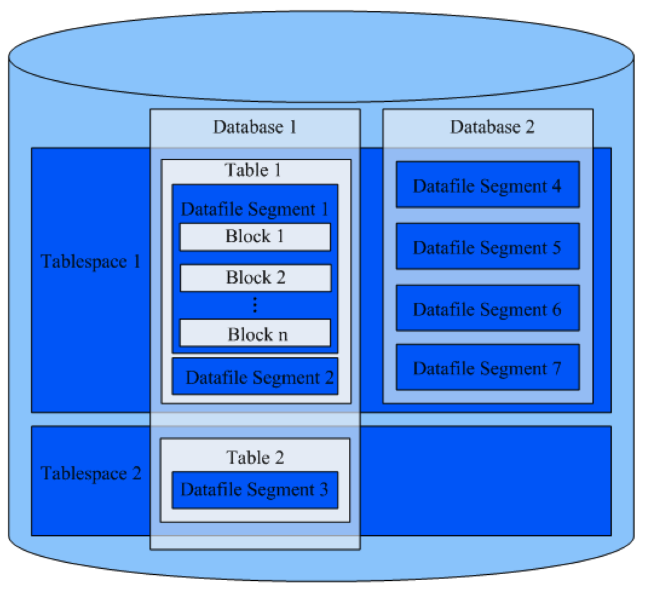
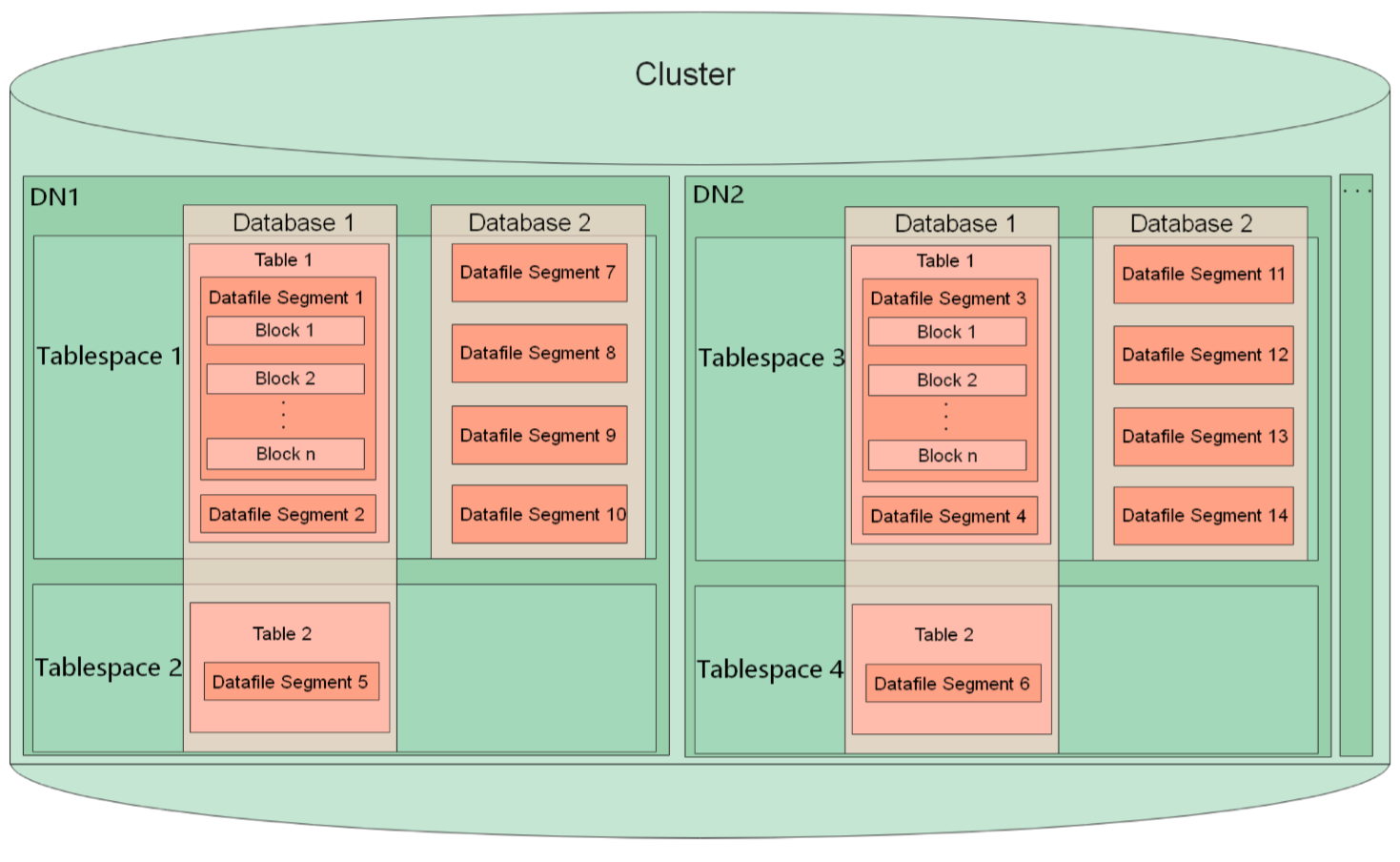
数据节点DN详细内部结构如下图。可以看到,在分布式结构下,DN1与DN2的节点中存储的数据并不相同,分布式系统会通过Hash算法计算数据存储位置。
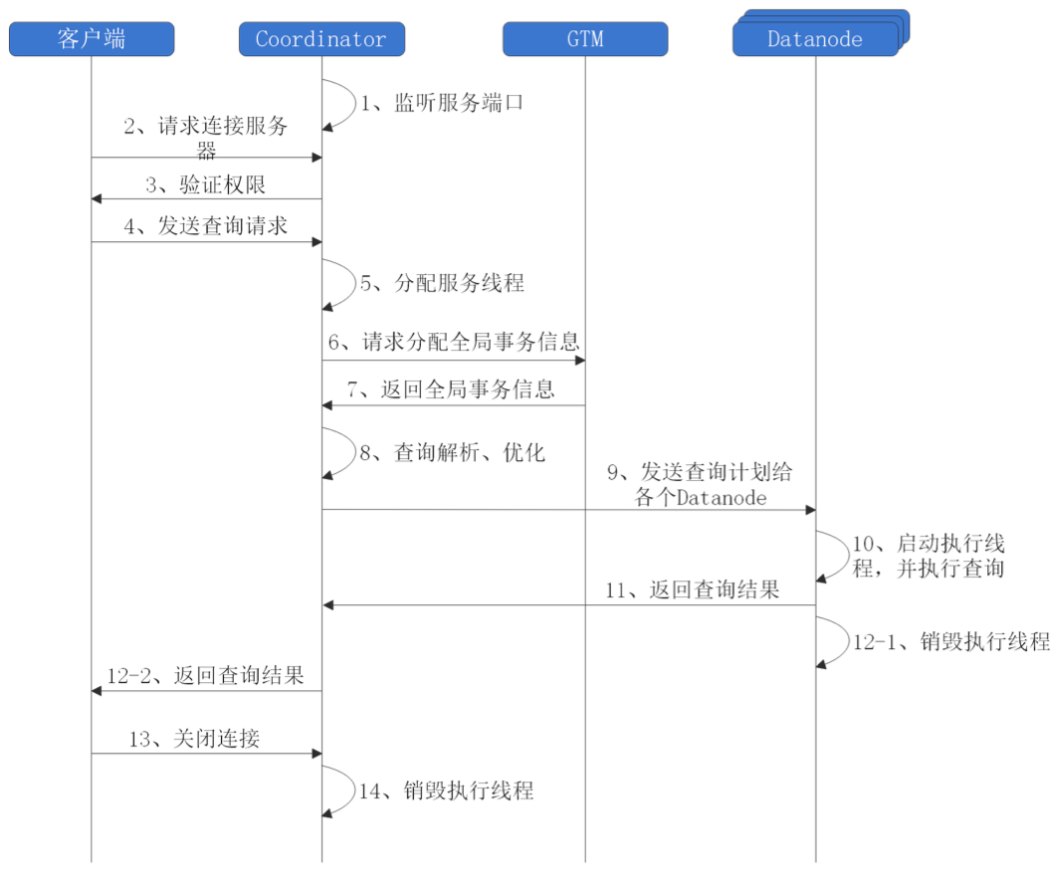
在分布式模式下,一个服务响应流程可以参考下图。Database Server通过监听服务接口监听客户端,当客户端发送请求连接服务端时,服务端会进行鉴权操作。如果客户端拥有权限,则允许发送查询请求。服务端在接受到客户端的查询请求后,会由协调节点分配一个服务线程。协调节点向全局事务管理器GTM请求分配全局事务信息,并由GTM返回全局事务信息。协调节点执行查询的解析、优化,将查询计划发给各个数据节点。由数据节点启动执行线程并执行查询,返回查询结果,销毁执行线程。协调节点接收到数据节点返回的查询结果后,将其返回给客户端。客户端获取到结果,关闭连接,协调节点销毁执行线程。
上面的查询过程可以用下图来简化表示。
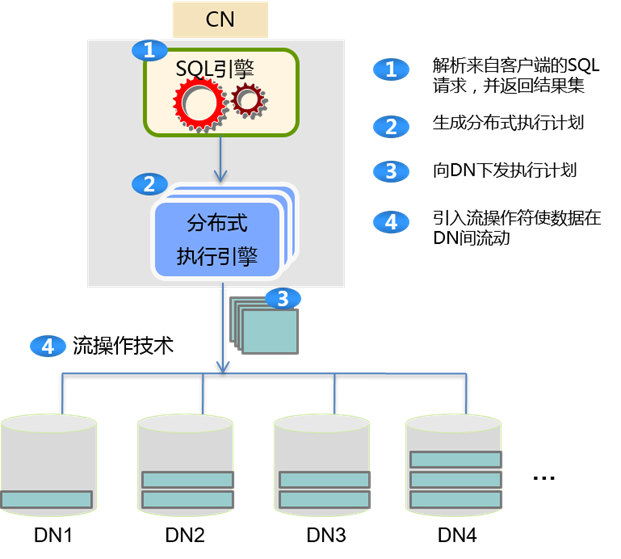
上图中, 可看到不同DN中存储了不同的数据。但这样会导致分布式架构下的数据可用性等问题。
比如
1.当需要增删节点时, 如何保证整体数据的完整性, 以及如何减小数据迁移的成本
2.某一个节点挂掉后, 整体数据完整性如何解决
对于问题1. 可以想到一致性Hash算法
一致性哈希是指将「存储节点」和「数据」都映射到一个首尾相连的哈希环上,如果增加或者移除一个节点,仅影响该节点在哈希环上顺时针相邻的后继节点,其它数据也不会受到影响。
详细介绍可参考文章https://xie.infoq.cn/article/0257506ed093aa1a0a67b44ae
对于问题2. 似乎只有当所有DN数据都一致的情况下才能解决。
5.2.4 DN数据分布策略
GaussDB 分布式架构下, 提供了四种DN数据分布策略.
可以在建表的时候指定:REPLICATION、HASH、RANGE、LIST 。
id int
) distribute by replication;
create table test2 (
id int
) distribute by hash(id);
HASH 散列
将数据通过Hash方式散列到集群中的所有DN实例上
适用场景: 数据量较大的表
GaussDB的hash分布采用类似一致性hash的方式,数据通过两层映射,第一层通过hash映射把数据映射到N个hash bucket中,或者叫vnode中;第二层映射把vnode映射到物理的datanode上。扩容时,只需要调整二层映射,保证数据搬迁最小:数据只会搬迁到新节点,已有节点之间不会互相搬迁数据;
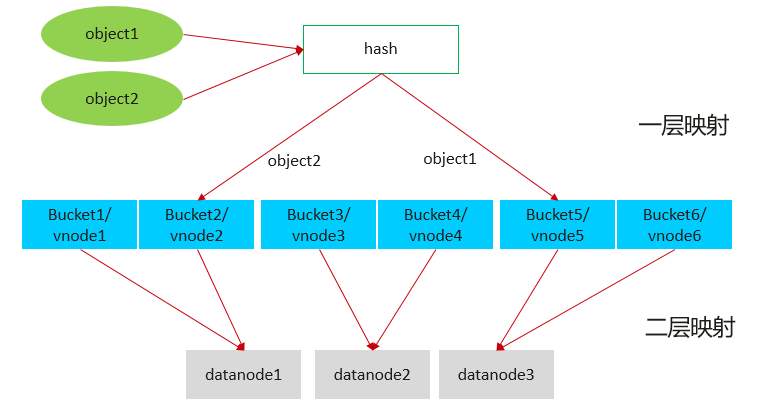
分布键选择原则
对于数据分布来讲,分布键的选择至关重要,不合适的分布键会导致数据倾斜,导致木桶效应。分布键的选择一般遵循如下原则:
1.尽量选择distinct值比较多的列,保证数据均匀分布。分布均匀是为了避免木桶效应,各个节点对等执行。
2.尽量选择Join列或group 列做分布列。尽量选择Join列或group 列是为了避免数据节点之间数据流动,提高性能。
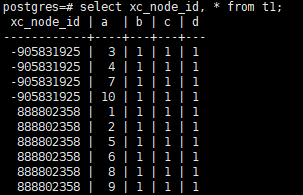
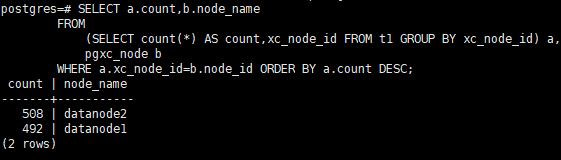
数据分布检查
通过如下方法,可以查询数据存储在哪个DN,其中xc_node_id就是DN的内部标识,取值于系统表pgxc_node的xc_node_id列。
FROM
(SELECT count(*) AS count,xc_node_id FROM tablename GROUP BY xc_node_id) a,
pgxc_node b
WHERE a.xc_node_id=b.node_id ORDER BY a.count DESC;
Replication 复制
每个DN实例都拥有一份全量的数据
适用场景 数据量较小, 更新频率比较低的表, 比如字典表